 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHA-VLN: A Benchmark for Human-Aware Navigation in Discrete-Continuous Environments with Dynamic Multi-Human Interactions, Real-World Validation, and an Open Leaderboard
Mar 18, 2025



Vision-and-Language Navigation (VLN) systems often focus on either discrete (panoramic) or continuous (free-motion) paradigms alone, overlooking the complexities of human-populated, dynamic environments. We introduce a unified Human-Aware VLN (HA-VLN) benchmark that merges these paradigms under explicit social-awareness constraints. Our contributions include: 1. A standardized task definition that balances discrete-continuous navigation with personal-space requirements; 2. An enhanced human motion dataset (HAPS 2.0) and upgraded simulators capturing realistic multi-human interactions, outdoor contexts, and refined motion-language alignment; 3. Extensive benchmarking on 16,844 human-centric instructions, revealing how multi-human dynamics and partial observability pose substantial challenges for leading VLN agents; 4. Real-world robot tests validating sim-to-real transfer in crowded indoor spaces; and 5. A public leaderboard supporting transparent comparisons across discrete and continuous tasks. Empirical results show improved navigation success and fewer collisions when social context is integrated, underscoring the need for human-centric design. By releasing all datasets, simulators, agent code, and evaluation tools, we aim to advance safer, more capable, and socially responsible VLN research.
Contrastive Adaptation Network for Unsupervised Domain Adaptation
Jan 04, 2019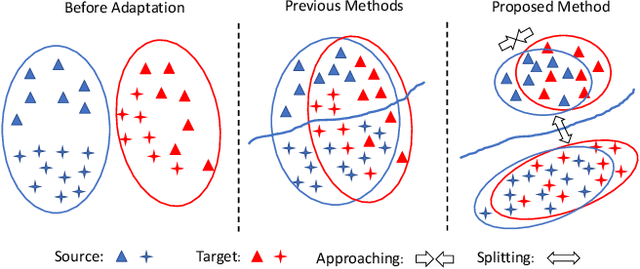
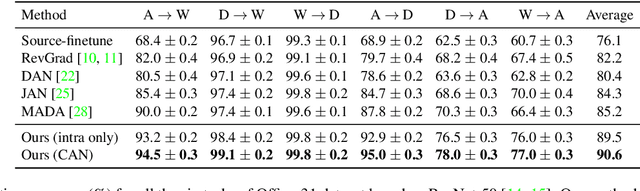
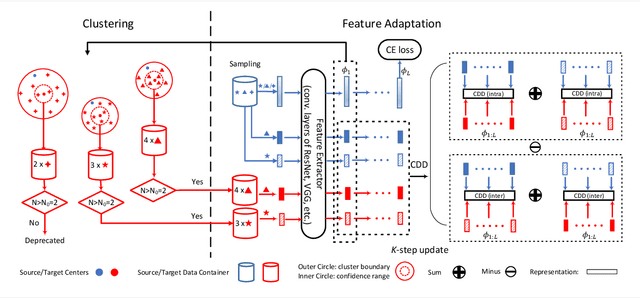
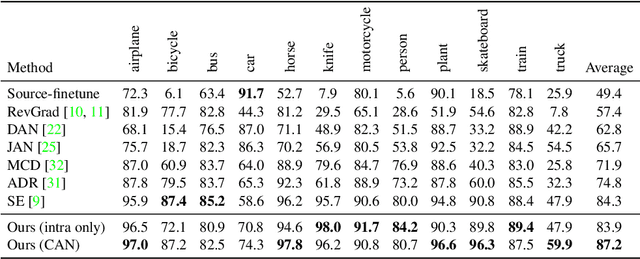
Unsupervised Domain Adaptation (UDA) makes predictions for the target domain data while manual annotations are only available in the source domain. Previous methods minimize the domain discrepancy neglecting the class information, which may lead to misalignment and poor generalization performance. To address this issue, this paper proposes Contrastive Adaptation Network (CAN) optimizing a new metric which explicitly models the intra-class domain discrepancy and the inter-class domain discrepancy. We design an alternating update strategy for training CAN in an end-to-end manner. Experiments on two real-world benchmarks Office-31 and VisDA-2017 demonstrate that CAN performs favorably against the state-of-the-art methods and produces more discriminative features. We will release the code soon.